Greetings-
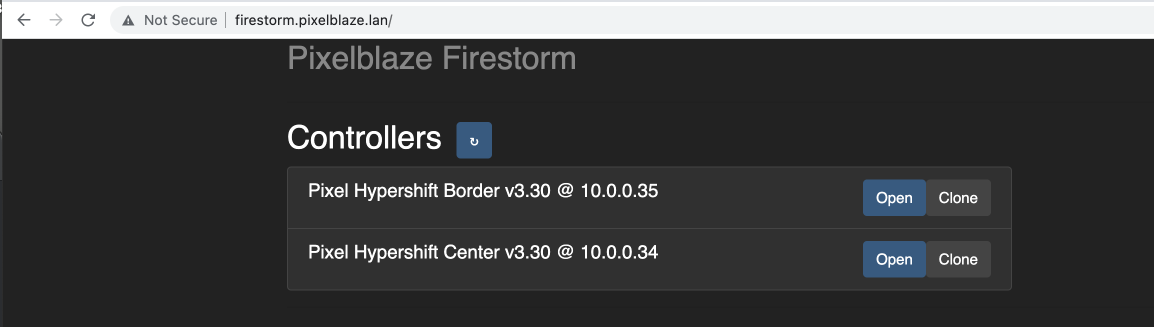
I am running a few PixelBlazes in our residence, two Picos, and three PB Standards. I’m running Firestorm on a hardwired raspberry pi with 8 GB of ram, on port 80, using the document on the Firestorm repo.
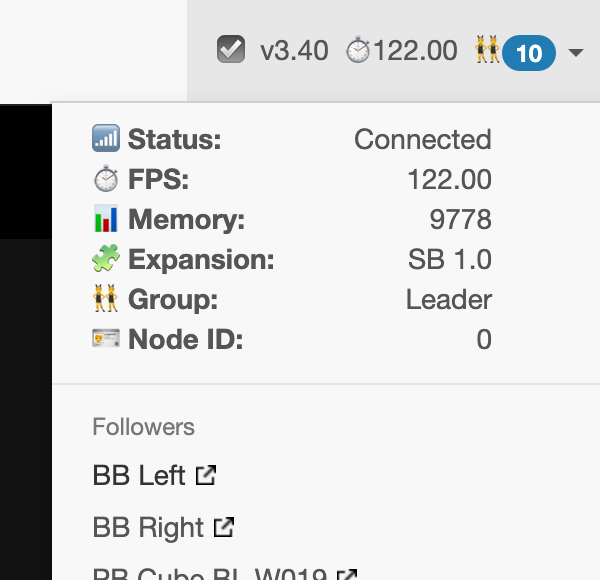
One of the PB has the Sensor Expansion board, and I am thinking of installing another sensor expansion board on another PB Standard (or Pico, depending on how wild I’m feeling) if I can figure out what’s going on with this one PB when Firestorm is running in pm2, and connected to the network.
It smells like a WebSocket or UDP flood, but I do not know where to start troubleshooting this without busting out something like Wireshark to sniff the network and see what’s happening.
Essentially the short and sweet is I have all the PixelBlazes ( standard and Pico) set to turn and off at certain times in the evening. Firestorm remains on, which I have a few feature requests for; I might be willing to contribute upstream for said features in time. I’ll save those for another thread at a later time;
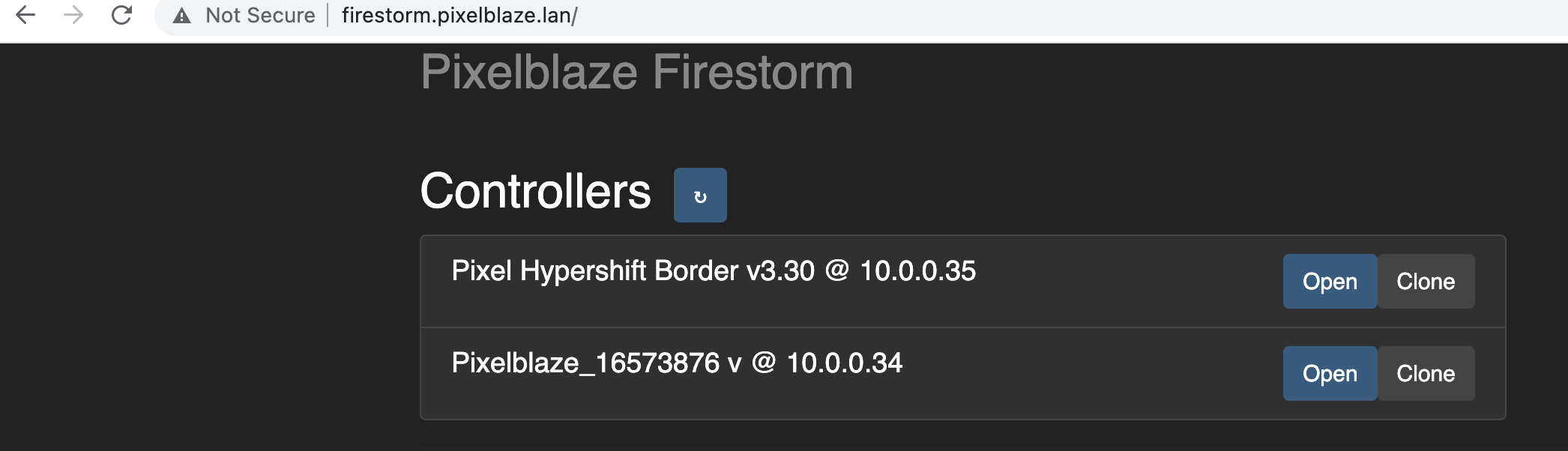
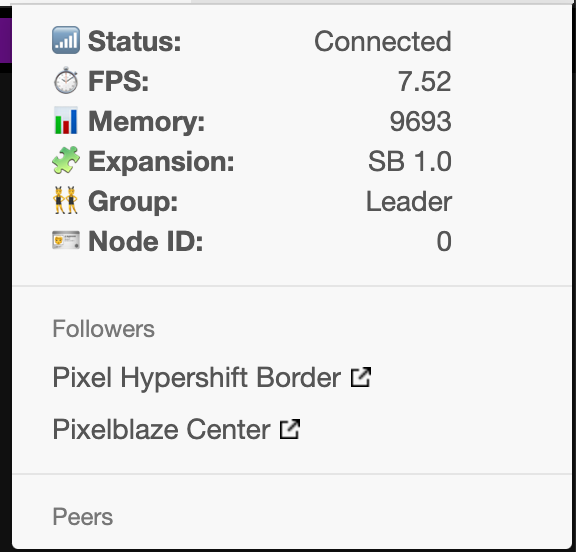
The PixelBlaze attached to the SensorBoard cannot be resolved by IP address or local DNS queries ( configured on my pfSense network router) or on any device across browsers. Additionally, discover.electromage.com will report that PixelBlaze with the SB attached to it was last seen 800+ minutes ago (this varies from whenever I decide I want some blinky in my life during the day).
All of the Pixelblazes will turn back on as usual when scheduled, but they are not in sync with the Firestorm playlist, which can be a bit wild since I have a few running simultaneously. Hence the strong desire to have them all synced with Firestorm, or in the interim, I’ll have to settle with just a single pattern until I can figure out how to resolve the Firestorm issue.
To resolve the network resolution via IP address and local DNS queries and through the discover.electromage.com service, I have to disconnect the power to the PixelBlaze with the SensorBoard attached and effectively reboot it. I need to reboot the Firestorm server using the pm2 service and entirely disconnect the Pi from the network, effectively stopping whatever is clogging the WebSockets on the PB.
Eventually, I can reconnect the Firestorm to the network, and the PixelBlazes will sync up as desired, and all is well in the world.
Any ideas on how to troubleshoot this so that we might be able to resolve this for other users? Thanks for your time. ![]()
For further information, each PIxelblaze is running v3.30, the PixelBlaze with the SB attached is HW v3.6, and the Picos are HW v1.7, and running a PB v3.4 w/o the SB.